
Parquet Metadata: An Intro to data serialisation
Published:
Introduction
Engaging daily with Parquet, I find it fascinating to delve into the intricate workings spanning from data residing in memory to its storage as byte arrays in HDFS block storage or within object stores like ADLS or S3, facilitated by a block storage style wrapper interface such as ABFS or S3a. To grasp the serialization process of Parquet, it’s imperative to explore how data is stored on disk and the consequential impacts on performance and cost. Let’s embark on a detailed exploration of Parquet’s serialisation, tracing its journey from the rudimentary realms of JSON and XML to its definition with Thrift.
Textual serialisation formats
Textual serialization formats play a crucial role in data encoding, offering versatile ways to represent structured information in a human-readable format. These formats facilitate efficient data interchange and storage across various systems and applications. Examples of textual serialization formats include JSON (JavaScript Object Notation), XML (eXtensible Markup Language), YAML (YAML Ain’t Markup Language), and CSV (Comma-Separated Values). These formats focus on human readibility over encoding cost. A typical textual format encoding would look like the following:
## Sample JSON
{"key":123}
## Character encoding UTF-8
{ " k e y " : 1 2 3 }
## Byte Representation
7B 22 6B 65 79 22 3A 31 32 33 7D
## Byte Array:
[0x7B, 0x22, 0x6B, 0x65, 0x79, 0x22, 0x3A, 0x31, 0x32, 0x33, 0x7D]
To encode a simple json it would take 11 bytes. Could you we do any better? Even a 10% storage cost reduction would bring a lot of performance and cost advantage when operating at terabyte scale.
Binary serialisation formats
Binary-based serializations are encoding methods that represent data in a binary format, which is more efficient in terms of space and processing compared to text-based formats. Binary-based serialization methods offer advantages in terms of efficiency, speed, and support for complex data structures, making them popular choices for various applications, especially in distributed systems and big data processing. Let’s take the above example and look at the binary-encoded version:
## Sample JSON
{"key":123}
## MessagePack encoded JSON's Byte Array Representation
\x81\xa3key{
The encoded version here would take 6 bytes. Saving using around 45% of storage cost. Typical binary serialisation methods are as follows:
- Protocol Buffers (protobuf)
- Apache Avro
- Apache Thrift
- MessagePack
- BSON (Binary JSON)
Based on what data you have and how you encode it. The results could vary. But it can be said, mostly binary methods are space efficient, especially when human readability is not important.
Parquet’s serialisation method
When parquet was in incubation, it was clear for a format that is meant for data processing, we can sacrifice human readability over space efficiency when file is stored. Also, at its core it is designed for hadoop ecosystem, since hadoop was always a thrift heavy ecosystem it was an obvious choice for parquet to go in Apache Thrift direction. To understand why parquet uses Apache Thrift we need to understand what it is and how it works.
What is Apache Thrift?
Since we have established, that a binary serialisation method are more efficent over textual serialisation methods. We need to ensure that this methods is programming language agnostic i.e. we need an IDL (Interface Definition Language) that could serve as transparent, high-performance bridge across many programming languages. Google was first to the scene and developed Protocol Buffers. Protobuf is language neutral way to encode and decode information. Facebook followed a similar suit, with Thrift. Thrift whitepaper defines the following goals for an IDL and in this case thrift to be usable by teams at Facebook:
- Types: A common type system must exist across programming languages without requiring that the application developer use custom Thrift datatypes or write their own serialization code. Example, C++ programmer should be able to transparently exchange a strongly typed STL map for a dynamic Python dictionary. Neither programmer should be forced to write any code below the application layer to achieve this.
- Transport: Each language must have a common interface to bidirectional raw data transport. The specifics of how a given transport is implemented should not matter to the service developer. Example, The same application code should be able to run against TCP stream sockets, raw data in memory, or files on disk
- Protocol: Datatypes must have some way of using the Transport layer to encode and decode themselves. Again, the application developer need not be concerned by this layer. Example, Whether the service uses an XML or binary protocol is immaterial to the application code. All that matters is that the data can be read and written in a consistent, deterministic matter.
- Versioning: For robust services, the involved datatypes must provide a mechanism for versioning themselves. Specifically, it should be possible to add or remove fields in an object or alter the argument list of a function without any interruption in service.
- Processors: Finally, we generate code capable of processing data streams to accomplish remote procedure calls.
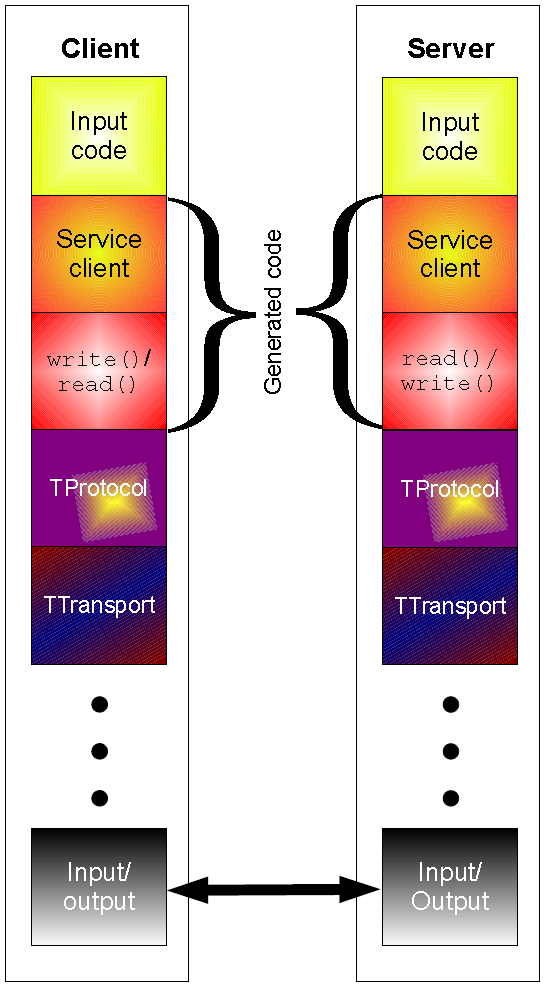
Example Code:
// Let's call this file multiplcation.thrift
typedef i32 int // We can use typedef to get pretty names for the types we are using
service MultiplicationService
{
int multiply(1:int n1, 2:int n2),
}
Generate code to use in your application:
thrift --gen java multiplication.thrift
thrift --gen py multiplication.thrift
Parquet and Thrift
Parquet uses thrift to define it’s metadata (Thrift File). This enables parquet to support all languages that can leverage thrift and since thrift is very extendable it can add support of new languages over time. For example, Rust is supported thrift and we can already see the benefits of using rust to write in-memory operations on top of parquet (Comet). Another example for the same is, C++ implementation of Parquet for in-memory analytics (Arrow) that is behind the Pandas UDF feature in Spark as it allows almost no latency of serialisation of object between python and JVM.
Parquet’s Metadata
A few key concepts we need to define regarding Parquet:
- File: A HDFS file that must include the metadata for the file.
- Row group: A logical horizontal partitioning of the data into rows. A row group consists of a column chunk for each column in the dataset.
- Column chunk: A chunk of the data for a particular column. They live in a particular row group and are guaranteed to be contiguous in the file.
- Page: Column chunks are divided up into pages. A page is conceptually an indivisible unit (in terms of compression and encoding). There can be multiple page types which are interleaved in a column chunk.
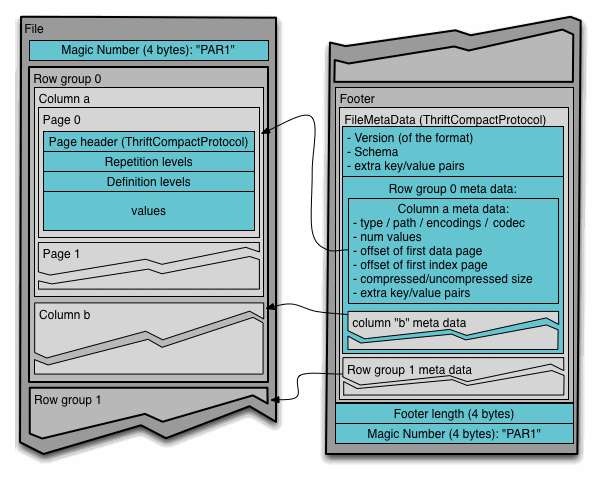
Hierarchically, a file consists of one or more row groups. A row group contains exactly one column chunk per column. Column chunks contain one or more pages. Let’s go over an example:
4-byte magic number "PAR1"
<Column 1 Chunk 1 + Column Metadata>
<Column 2 Chunk 1 + Column Metadata>
...
<Column N Chunk 1 + Column Metadata>
<Column 1 Chunk 2 + Column Metadata>
<Column 2 Chunk 2 + Column Metadata>
...
<Column N Chunk 2 + Column Metadata>
...
<Column 1 Chunk M + Column Metadata>
<Column 2 Chunk M + Column Metadata>
...
<Column N Chunk M + Column Metadata>
File Metadata
4-byte length in bytes of file metadata (little endian)
4-byte magic number "PAR1"
In the example provided, the table consists of N columns organized into M row groups. Within the file metadata, the locations of all column metadata start positions are specified. Further elaboration on the contents of the metadata is available in below. To facilitate efficient single-pass writing, the metadata is written after the data. Consequently, readers are advised to commence by reading the file metadata to identify the relevant column chunks. Subsequently, the column chunks should be read in sequential order for optimal processing.
Unit of parallelization
Based on the choice of tool to process parquet tuning one of the following helps improve the performance:
- Distributed Processor - Distributed processor operations parallelise on File/Row Group level
- IO - IO operations occur on Column chunk level
- Encoding/Compression - Encoding of information happens on Page level
Here is a detailed layout of a parquet file:
Metadata types
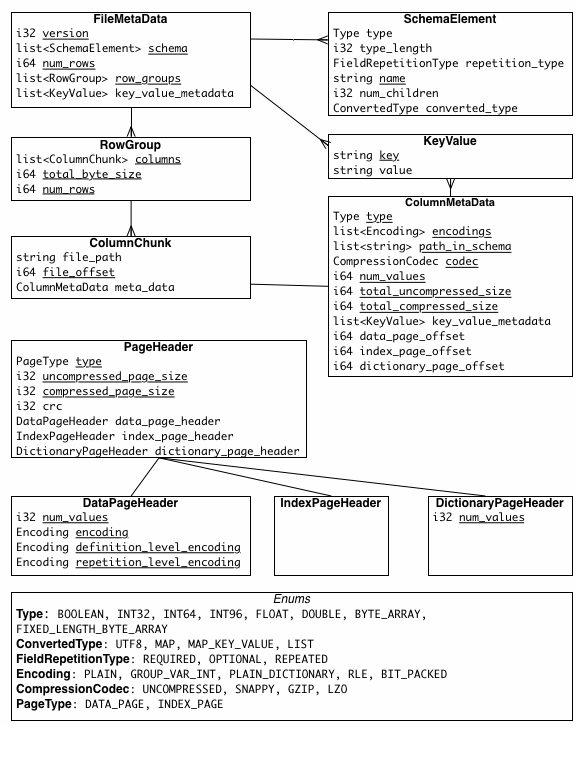
All parquet metadata is seralised using TCompactProtocol. There are 3 types of metadata in parquet:
- file metadata
- column metadata
- page header metadata
Here is a logical flow of relationship between various concepts inside parquet file:
Takeaway
This blogpost introduces data serialisation, a brief intro into apache thrift and how parquet leverages it to define a language independent parquet metadata. Here are some takeaways:
- Binary serialisation formats are way faster than Textual serialisation methods
- Apache thrift as a serialisation format is really useful for fast and efficent data transfer
- Parquet has many aspects around which it can be tuned for performance from page level to file level
I would recommend reading the parquet-format repo for deep-dives. It is a very well written documentation of parquet and this article only shines light on some aspects of it. In my next piece, I intend to delve into the realms of Logical types, Encryption, Encoding, Compression, Page Indexing, and the application of Bloom Filters within Parquet.